Python +BeautifulSoup 抓取豆瓣电影TOP250页面数据
iamdu2019-12-10 09:59:46Python 浏览: 284072
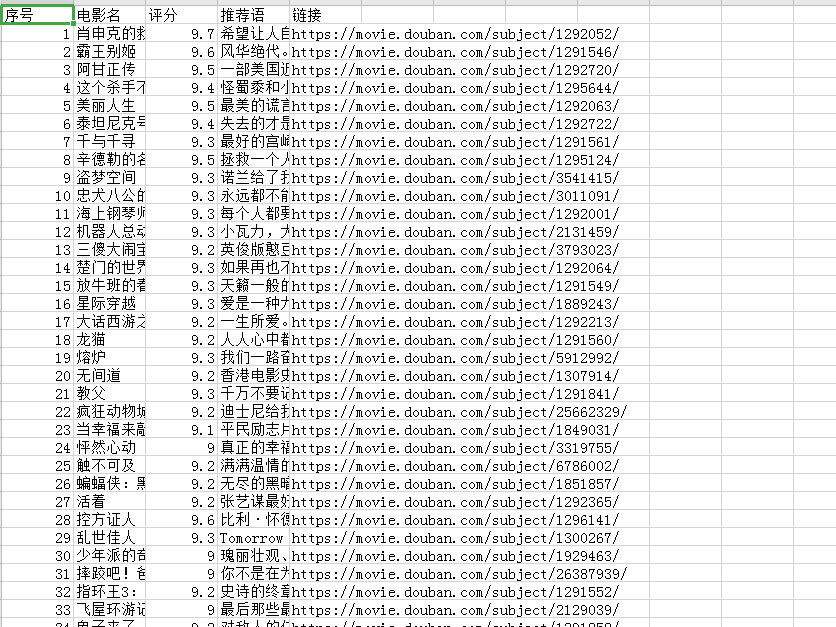 Python运行后抓取到的数据写入crv文件
Python运行后抓取到的数据写入crv文件
#调用crv模块 最后把得到的数据写入crv
import csv
# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 模拟页头信息
fakeHeaders = {'User-Agent': "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"}
N = 10 #网站分页结构一样 代表扒10个页面 也就是扒到第10页
films2 = [] #空的数组来存储全部页数的数据
for i in range(1,N+1):
start = (i-1)*25 #分页的页面变量 第1页是0 第2页25 第3页50......
# headers 有些网站禁止爬虫,加上这个语句可以模拟人工浏览
res =requests.get('https://movie.douban.com/top250?start='+ str(start) +'&filter=', headers=fakeHeaders)
print(res.status_code)
# 返回状态码,200代表成功
html=res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过匹配属性class='books'提取出我们想要的元素
items = soup.find('ol',class_='grid_view').find_all('li')
#建立一个空的数组来存储每一页的遍历数据
films = []
# 遍历列表items
for item in items:
#print(item)
# # # 提取序号
movie_num = item.find('em')
# # 提取电影名
movie_name = item.find('span',class_='title')
# # 提取评分
movie_rating = item.find('span',class_='rating_num')
# # 提取推荐语
movie_quote = item.find('span',class_='inq')
# # 提取链接 find()用法就是提取第一个 后面的不会再去查询
movie_link = item.find('a')
#最终打印结果,可以使用str.strip()去除特殊字符串。
# 比如,使用.strip()即可去掉' 我是杨幂\n'文字前面的空格与后面的换行。
film = [str.strip(movie_num.text),str.strip(movie_name.text),str.strip(movie_rating.text),
str.strip(movie_quote.text),str.strip(movie_link['href'])]
films.append(film)
films2.extend(films)
print(len(films2)) #打印数据长度 这里输出250
print(films2) #打印数组 这里会以列表的形式来呈现
#得到的数据写入crv文件
with open('douban.csv', 'a', newline='',encoding='utf-8')as csvfile: #encoding='utf-8'很关键,要不可能会出现乱码
#Mac用户要加多一个参数 encoding = 'GBK'
writer = csv.writer(csvfile, dialect='excel')
for dy in films2:
writer.writerow([dy[0],dy[1],dy[2],dy[3],dy[4]])
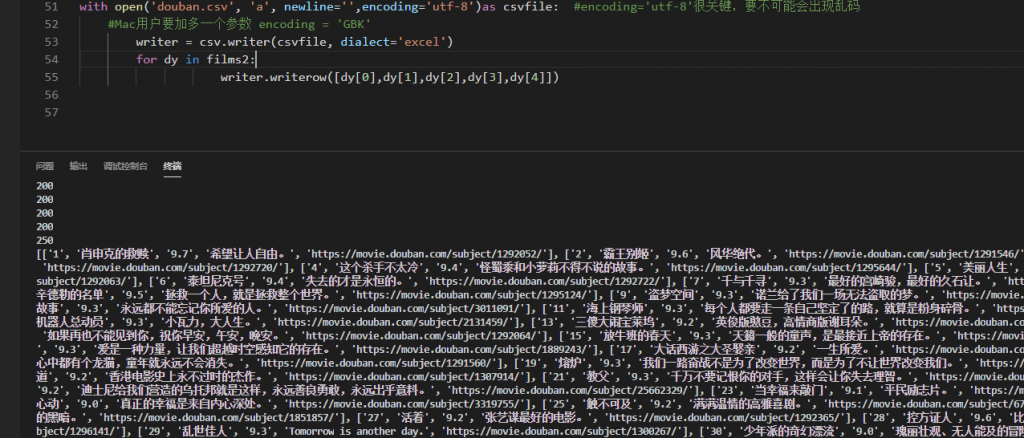 CMD界面执行完后的截图
CMD界面执行完后的截图





欢迎留下你的看法
共 0 条评论