
Python selenium提取数据的方法
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
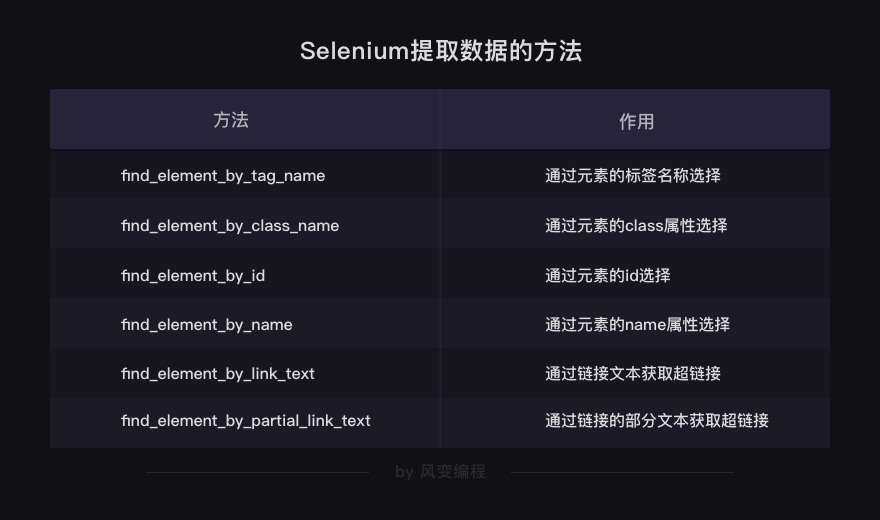
find_element_by_tag_name:通过元素的名称选择
# 如<h1>你好,蜘蛛侠!</h1>
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如<h1 class="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如<h1 id="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如<h1 name="hello">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如<a href="spidermen.html">你好,蜘蛛侠!</a>
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如<a href="https://localprod.pandateacher.com/python-manuscript/hello-spiderman/">你好,蜘蛛侠!</a>
# 可以使用find_element_by_partial_link_text('你好')扩展:
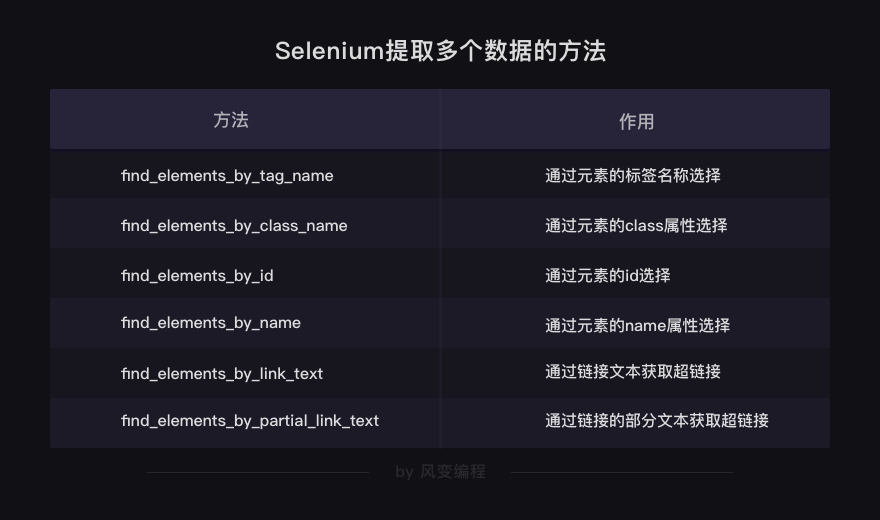
find_elements_by_link_text:#elements就是提取多个了Selenium + beautifulsoup 配合提取解析页面案例
# 下面是只能在你的本地运行的答案:
from selenium import webdriver # 从selenium库总调用webdriver模块
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome() # 声明浏览器对象
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 暂停两秒,等待浏览器缓冲
teacher = driver.find_element_by_id('teacher') # 定位到【请输入你喜欢的老师】下面的输入框位置
teacher.send_keys('必须是吴枫呀') # 输入文字
assistant = driver.find_element_by_name('assistant') # 定位到【请输入你喜欢的助教】下面的输入框位置
assistant.send_keys('都喜欢') # 输入文字
button = driver.find_element_by_class_name('sub') # 定位到【提交】按钮
button.click() # 点击【提交】按钮
time.sleep(1) # 等待一秒
pageSource = driver.page_source # 获取页面信息
soup = BeautifulSoup(pageSource,'html.parser') # 使用bs解析网页
contents = soup.find_all(class_="content") # 找到源代码Python之禅中文版和英文版所在的元素
for content in contents: # 遍历列表
title = content.find('h1').text # 提取标题
chan = content.find('p').text.replace(' ','') # 提取Python之禅的正文,并且去掉文字前面的所有空格
print(title + chan + '\n') # 打印Python之禅的标题与正文
driver.close()
云服务器大促销


明道云零代码企业应用平台


欢迎留下你的看法
共 0 条评论