
作者: iamdu
from selenium import webdriver from bs4 import BeautifulSoup import time # browser = webdriver.PhantomJS() browser = webdriver.Chrome() browser.get(‘h […]
2020-01-09Python
wordcloud是功能强大的词云展示第三方库。它不仅可根据文本中词语出现的频率等参数绘制词云,还可设定词云的字体,颜色,形状等。需要注意的是,wordcloud库在运行时,需要用到一些依赖库:包括matplotlib库以及图像处理库pillow库。因此,使用该库之前,务必先装好依赖库。和其他第三方 […]
2020-01-08Python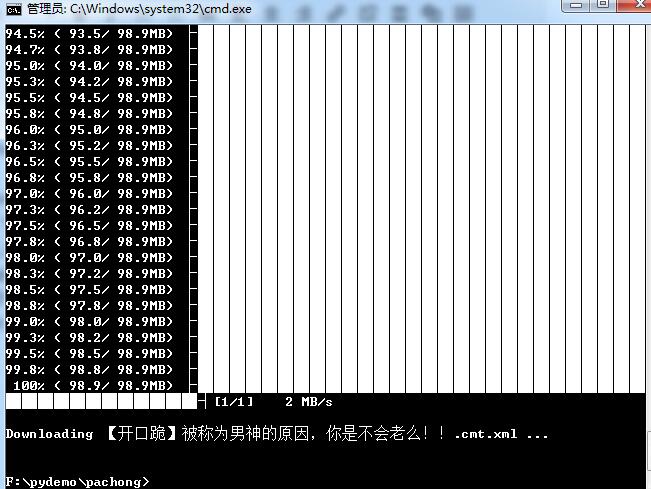
import sys from you_get import common as you_get #导入you-get库 directory = r’F:\pydemo’ #设置下载目录 url = ‘https://www.bilibili.com/video/av36631527/?spm_id […]
2020-01-08Python原文地址:https://www.jb51.net/article/167471.htm 很多时候我们需要过滤掉标点符号等特殊字符,网上虽然有一堆的方法,但是都没有找到一个非常满意的,有些过滤不了中文的标点符号,有些过滤不了英文的标点符号,有些过滤不全。 最后通过查看正则表达式文档,发现一个高效的办 […]
2020-01-08Python
scrapy 利用fiddler抓包批量下载【掌通家园】APP图片
关键点,利用fiddler抓取手机app里的数据接口参数 抓取后的数据 爬虫处理文件deal.py import scrapy import bs4 import random import csv import requests import json from ..items import ne […]
2020-01-07Pythonscrapy 域名过滤。DEBUG: Filtered offsite request to 解决方案
在做爬虫项目时,出现了一个问题,解析一个网站二次爬取时没有获取到数据,就写了一个测试程序试了下,测试程序如下 import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlS […]
2020-01-07Python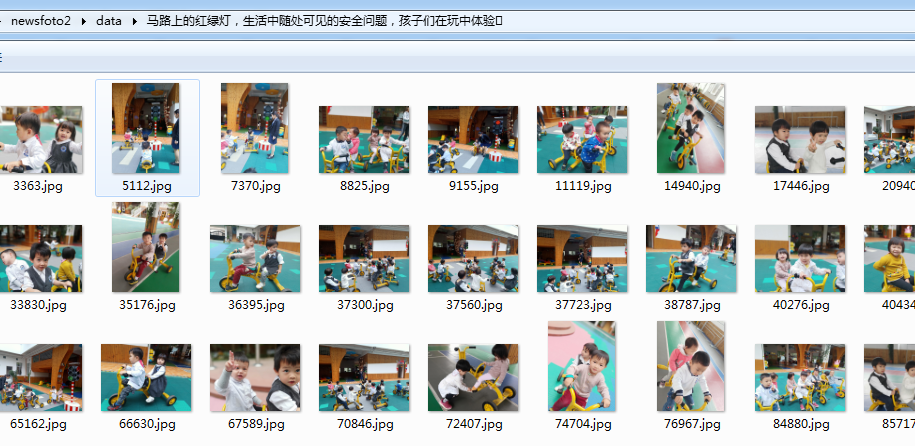
接口需要通过fiddler来抓包获取,下载下来的图片是原始高清大图无水印 爬虫处理页面deal.py import scrapy import bs4 import csv from ..items import newsfoto2Item # 需要引用mrleItem,它在items里面。因为是i […]
2020-01-07PythonSelenium+PhantomJS使用时报错原因及解决方案
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn(‘Seleni […]
2020-01-05Python
一、PhantomJS是什么?PhantomJS是一个基于webkit的javaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行javaScript代码。任何你可以基于在webkit浏览器做的事情,它都能做到。它不仅是个隐性的浏览器,提供了诸如css […]
2020-01-05Python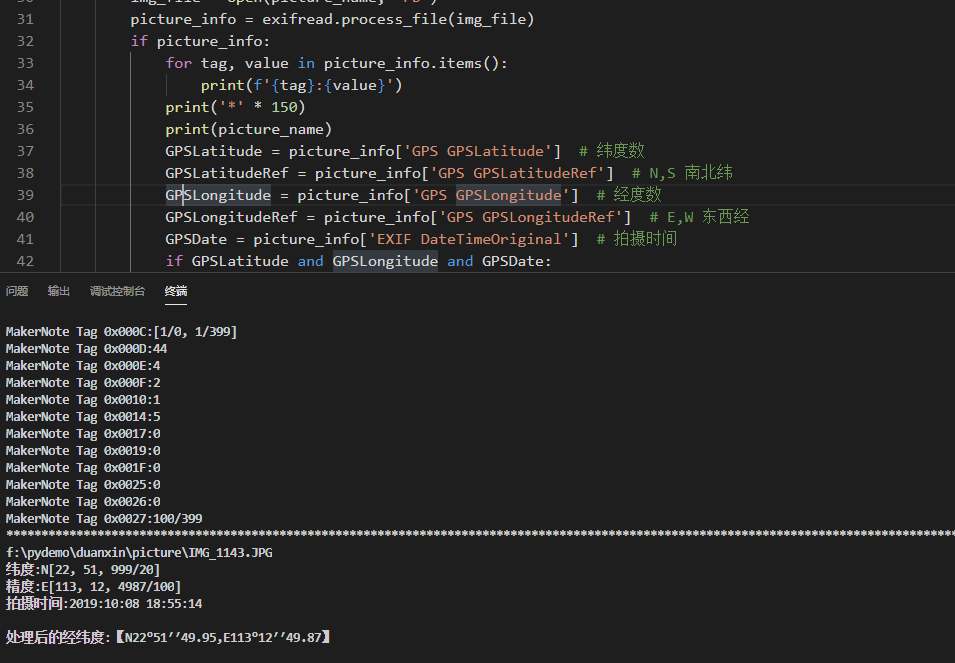
图片信息也是存在元数据的,网上官方称之为exif(exchange image file format),中文意思是交换图像文件格式。要注意的是有些图片是没有元数据的,比如压缩过的图片,元数据被破坏,无法探测,所以图片一定要是原图。如果你想用微信朋友圈,微博的图片来测试这次的代码,怕是没有希望了,因 […]
2020-01-05Python
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!