
Python +gevent 多线程抓取网站数据
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests。
start = time.time()
#记录程序开始时间。
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
#把8个网站封装成列表。
def crawler(url):
#定义一个crawler()函数。
r = requests.get(url)
#用requests.get()函数爬取网站。
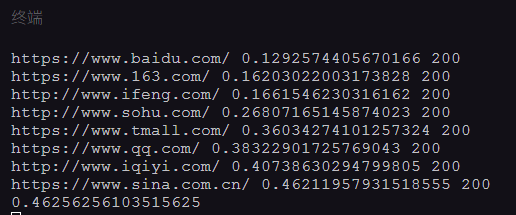
print(url,time.time()-start,r.status_code)
#打印网址、请求运行时间、状态码。
tasks_list = [ ]
#创建空的任务列表。
for url in url_list:
#遍历url_list。
task = gevent.spawn(crawler,url)
#用gevent.spawn()函数创建任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
#记录程序结束时间。
print(end-start)
#打印程序最终所需时间。
到这里,用gevent实操抓取8个网站我们已经完成,gevent的基础语法我们也大致了解。
那如果我们要爬的不是8个网站,而是1000个网站,我们可以怎么做?
用我们刚刚学的gevent语法,我们可以用gevent.spawn()创建1000个爬取任务,再用gevent.joinall()执行这1000个任务。
但这种方法会有问题:执行1000个任务,就是一下子发起1000次请求,这样子的恶意请求,会拖垮网站的服务器。

既然这种直接创建1000个任务的方式不可取,那我们能不能只创建成5个任务,但每个任务爬取200个网站?
假设我们有1000个任务,那创建5个任务,每个任务爬取200个网站的代码可以写成如下的样子(此代码仅做展示,并不可运行):
from gevent import monkey
monkey.patch_all()
import gevent,time,requests
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/'
……
#假设有1000个网址
]
def crawler(url_list):
#定义一个crawler()函数。
for url in url_list:
r = requests.get(url)
print(url,time.time()-start,r.status_code)
tasks_list = [ ]
#创建空的任务列表。
for i in range(5):
task = gevent.spawn(crawler,url_list[i*200:(i+1)*200])
#用gevent.spawn()函数创建5个任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
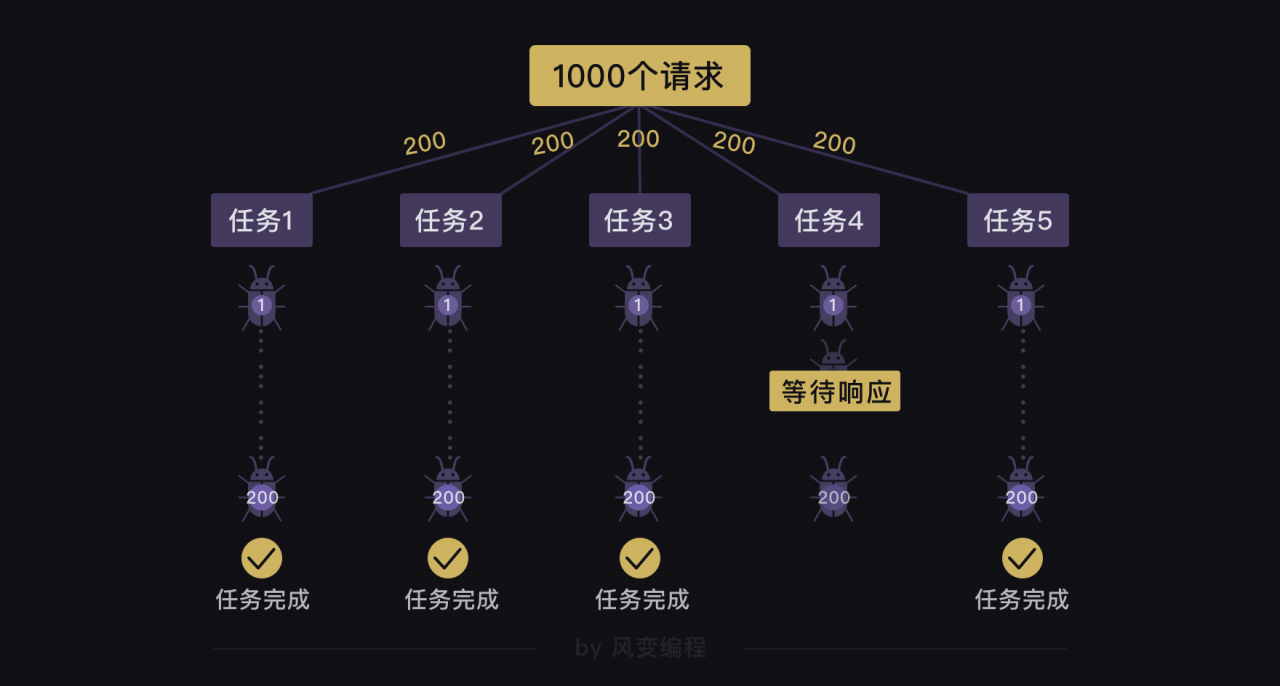
遗憾地告诉你,这么做也还是会有问题的。就算我们用gevent.spawn()创建了5个分别执行爬取200个网站的任务,这5个任务之间是异步执行的,但是每个任务(爬取200个网站)内部是同步的。
这意味着:如果有一个任务在执行的过程中,它要爬取的一个网站一直在等待响应,哪怕其他任务都完成了200个网站的爬取,它也还是不能完成200个网站的爬取。
======================================
引入终极解决方案:
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests
from gevent.queue import Queue
#从gevent库里导入queue模块
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
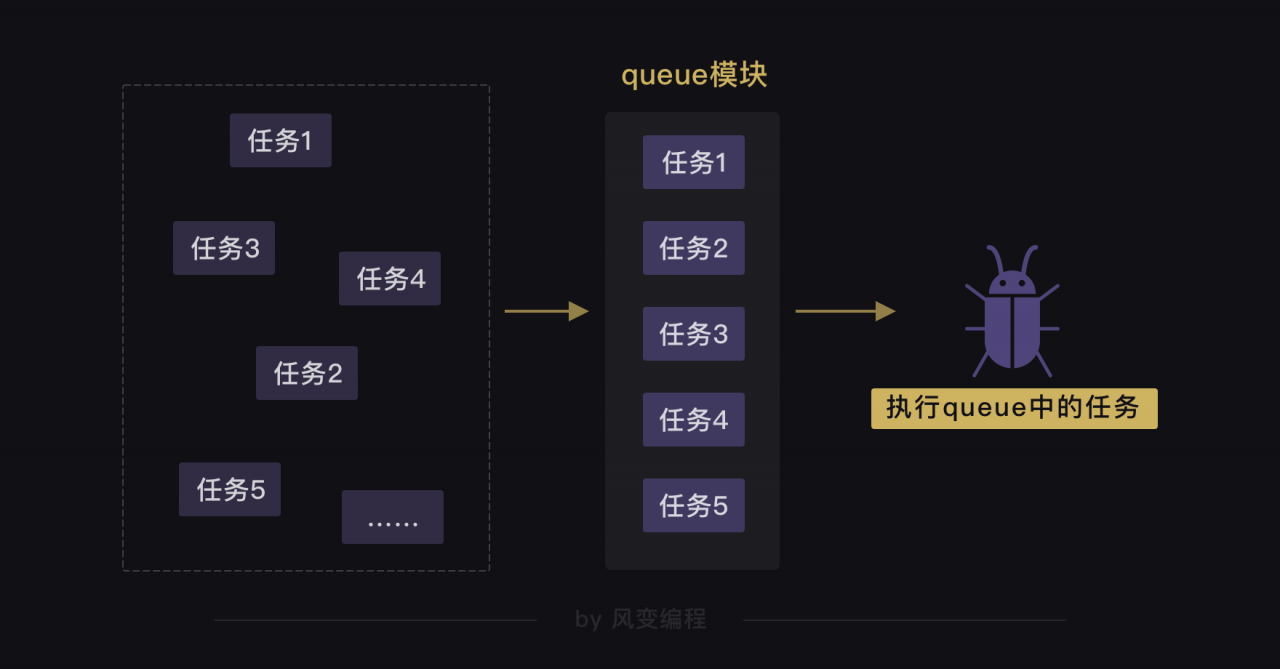
work = Queue()
#创建队列对象,并赋值给work。
for url in url_list:
#遍历url_list
work.put_nowait(url)
#用put_nowait()函数可以把网址都放进队列里。
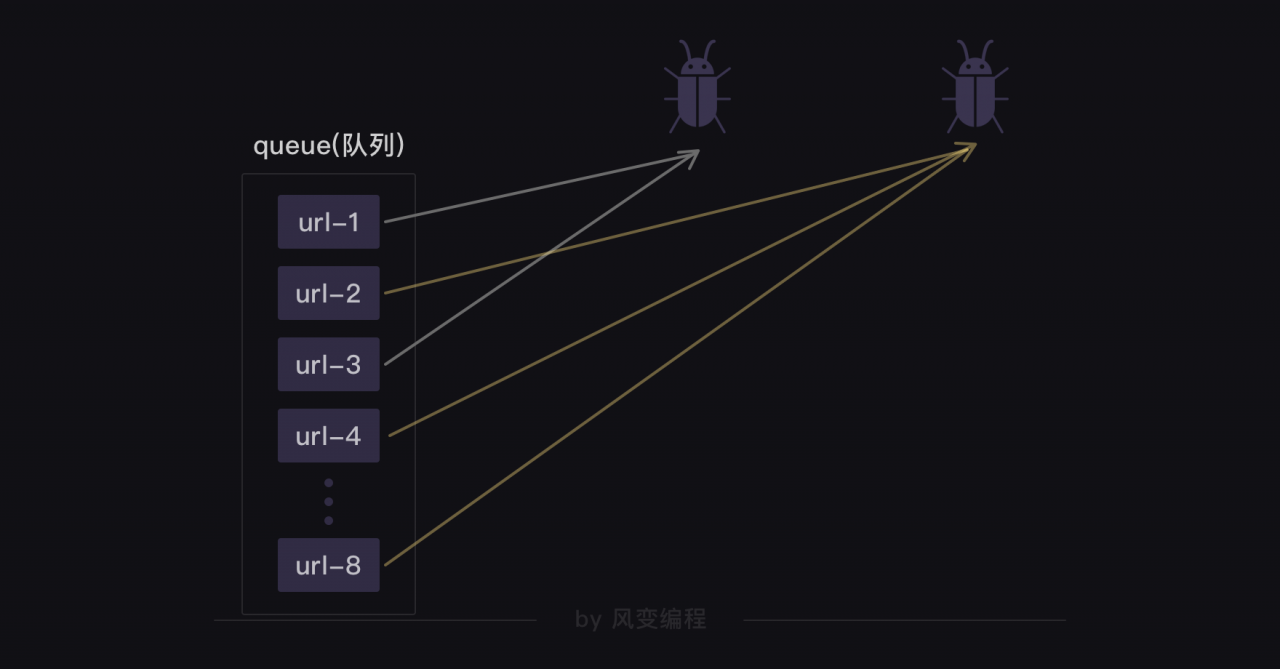
def crawler():
while not work.empty():
#当队列不是空的时候,就执行下面的程序。
url = work.get_nowait()
#用get_nowait()函数可以把队列里的网址都取出。
r = requests.get(url)
#用requests.get()函数抓取网址。
print(url,work.qsize(),r.status_code)
#打印网址、队列长度、抓取请求的状态码。
tasks_list = [ ]
#创建空的任务列表
for x in range(2):
#相当于创建了2个爬虫
task = gevent.spawn(crawler)
#用gevent.spawn()函数创建执行crawler()函数的任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#用gevent.joinall方法,执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
print(end-start)
云服务器大促销


明道云零代码企业应用平台


欢迎留下你的看法
共 0 条评论