
Python+scrapy实现自动爬取数据
在命令行输入scrapy命令新建项目
scrapy startproject mrle (mrle改成你需要的项目名字)
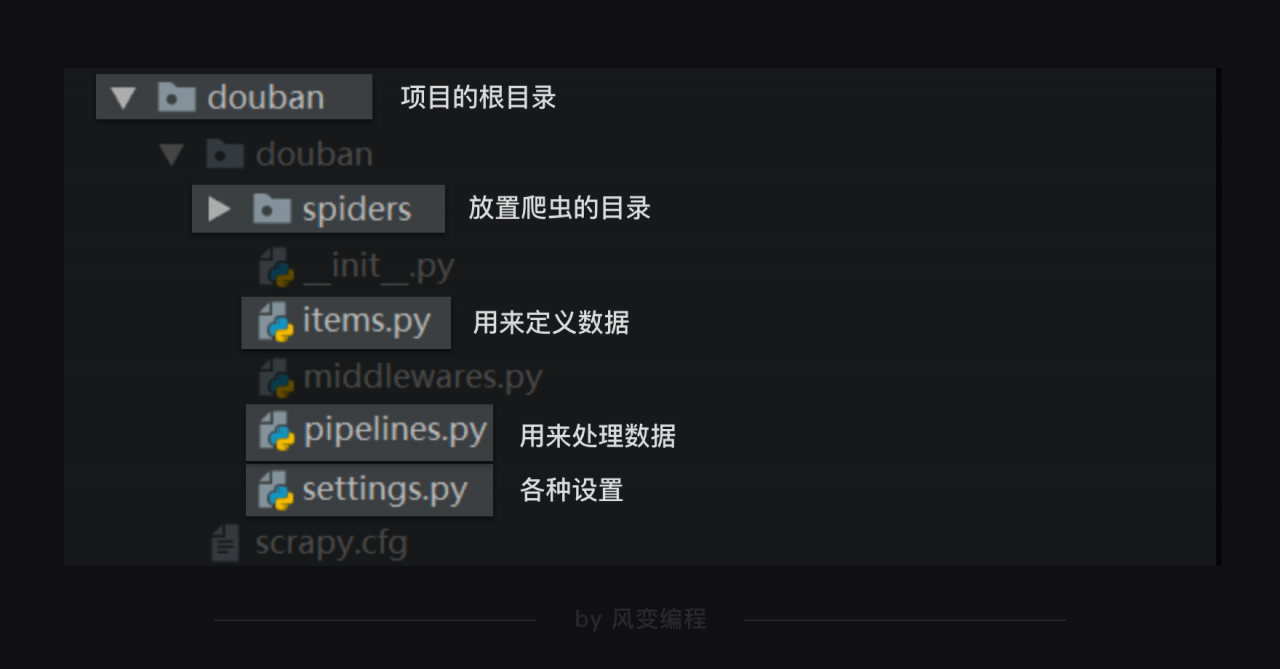
在spiders目录下新建一个deal.py 的文件来处理整个爬取内容的数据
import scrapy
import bs4
import csv
from ..items import mrleItem
# 需要引用mrleItem,它在items里面。因为是items在deal.py的上一级目录,所以要用..items,这是一个固定用法。
class mrleSpider(scrapy.Spider):
#定义一个爬虫类mrleSpider。
name = 'mrle'
#定义爬虫的名字。
allowed_domains = ['www.lovelifemrle.com']
#定义爬虫爬取网址的域名。
start_urls = []
#定义起始网址。
for x in range(3):
url = 'http://www.lovelifemrle.com/page/' + str(x+1)
start_urls.append(url)
#把豆瓣Top250图书的前3页网址添加进start_urls。
def parse(self, response):
#parse是默认处理response的方法。
bs = bs4.BeautifulSoup(response.text,'html.parser')
#用BeautifulSoup解析response。
datas = bs.find_all('div',class_="post-inner post-hover")
for data in datas:
#遍历data。
item = mrleItem()
item['pic'] = data.find('img')['src']
item['title'] = str.strip(data.find('h2').text)
item['time'] = data.find('time',class_='published updated').text
yield item
#yield item是把获得的item传递给引擎。默认的items.py 代码改成下面的
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class mrleItem(scrapy.Item):
#定义一个类mrleItem,它继承自scrapy.Item
pic = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
默认的settings.py文件修改,把抓取到的数据写入CSV文件里 ROBOTSTXT_OBEY = False 爬虫限制取消
# -*- coding: utf-8 -*-
# Scrapy settings for mrle project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'mrle'
SPIDER_MODULES = ['mrle.spiders']
NEWSPIDER_MODULE = 'mrle.spiders'
FEED_URI='./%(name)s.csv'
FEED_FORMAT='CSV'
FEED_EXPORT_ENCODING='ansi'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# Obey robots.txt rules
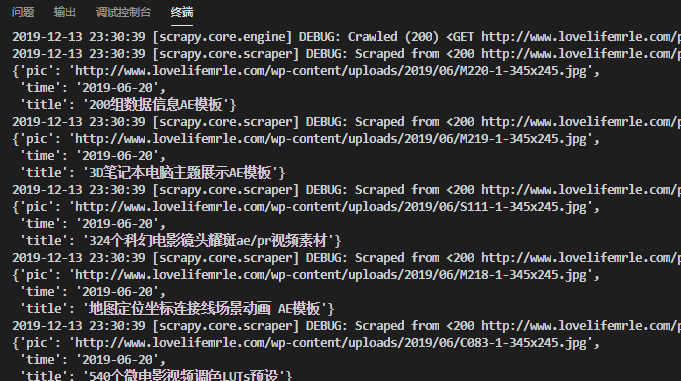
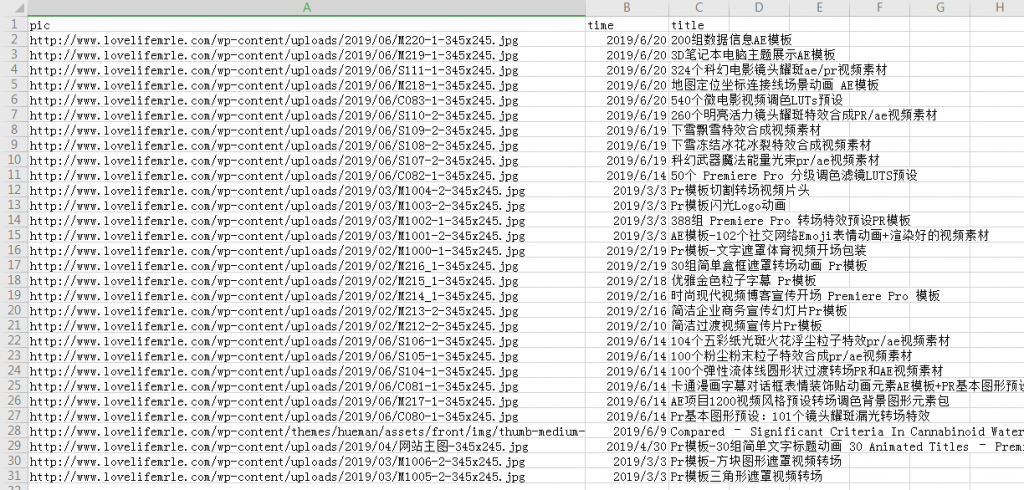
ROBOTSTXT_OBEY = False这样就全部搞定了,运行项目需要进入项目的目录,然后 命令:
scrapy crawl mrle
(mrle为你的项目名字)
===============================================================
如果需要进入详情页,则需要再加一个函数 deal.py写法如下
import scrapy
import bs4
import csv
from ..items import mrleItem
# 需要引用mrleItem,它在items里面。因为是items在deal.py的上一级目录,所以要用..items,这是一个固定用法。
class mrleSpider(scrapy.Spider):
#定义一个爬虫类mrleSpider。
name = 'mrle'
#定义爬虫的名字。
allowed_domains = ['www.lovelifemrle.com']
#定义爬虫爬取网址的域名。
start_urls = []
#定义起始网址。
for x in range(3):
url = 'http://www.lovelifemrle.com/page/' + str(x+1)
start_urls.append(url)
def parse(self, response):
#parse是默认处理response的方法。
bs = bs4.BeautifulSoup(response.text,'html.parser')
#用BeautifulSoup解析response。
datas = bs.find_all('div',class_="post-inner post-hover")
for data in datas:
#遍历data。
#获取文章页地址
url = data.find('a')['href']
yield scrapy.Request(url, callback=self.parse_job)
#用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parsejob方法。
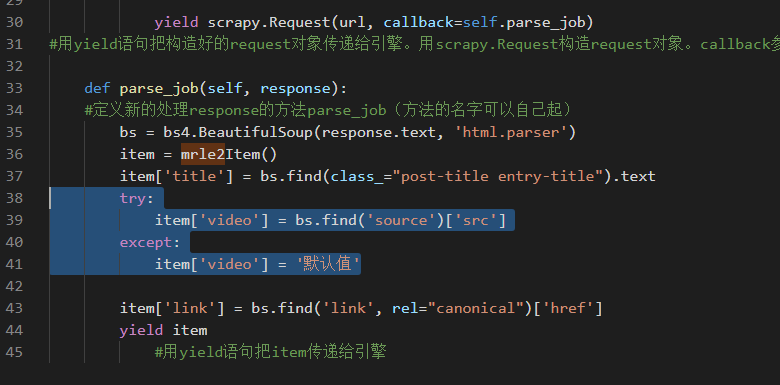
def parse_job(self, response):
#定义新的处理response的方法parse_job(方法的名字可以自己起)
bs = bs4.BeautifulSoup(response.text, 'html.parser')
item = mrleItem()
item['title'] = bs.find(class_="post-title entry-title").text
item['video'] = bs.find('source')['src']
item['link'] = bs.find('link', rel="canonical")['href']
yield item
#用yield语句把item传递给引擎有时候某些字段获取不到值,会导致该文章的其他数据也无法返回,这时候可以试试try:xxxx except:xxxx来解决。得不到值的字段默认数据。
云服务器大促销


明道云零代码企业应用平台


欢迎留下你的看法
共 0 条评论