
分类: Python
Python对文件的操作还算是方便的,只需要包含os模块进来,使用相关函数即可实现目录的创建。 主要涉及到三个函数 1、os.path.exists(path) 判断一个目录是否存在 2、os.makedirs(path) 多层创建目录 3、os.mkdir(path)  […]
2019-12-16Pythonfrom urllib import request request.urlretrieve(‘https://pic4.zhimg.com/80/v2-0abff609470f23e79b3b3d1f02b42b2f_hd.jpg’,’zhihu.jpg’) 这个函数可以方便的将网页上的一个文件保 […]
2019-12-16Python
import os path = ‘../pachong’ def get_file(path): # abspath获取目标文件夹的绝对路径 path = os.path.abspath(path) # listdir获取指定文件夹中的所有文件和文件夹组成的列表 files = os.listdi […]
2019-12-15Python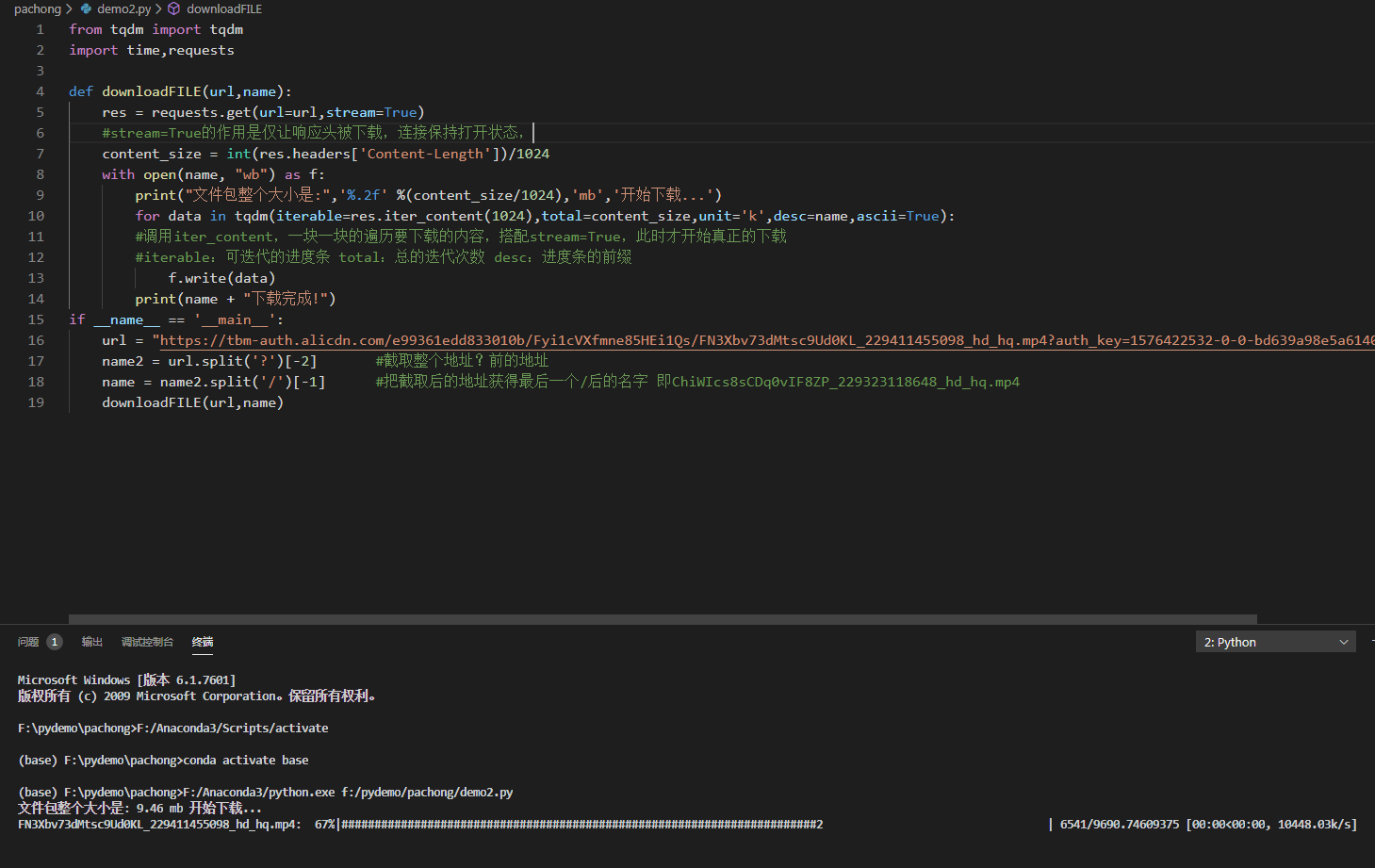
from tqdm import tqdm import time,requests def downloadFILE(url,name): res = requests.get(url=url,stream=True) #stream=True的作用是仅让响应头被下载,连接保持打开状态, cont […]
2019-12-15Python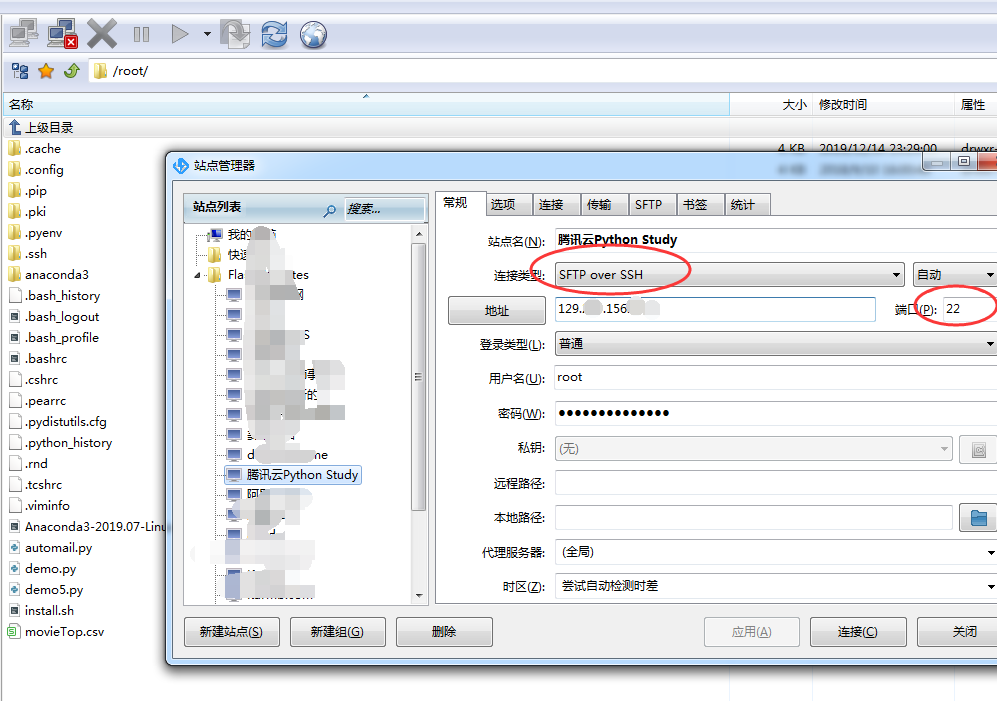
前段时间买了个腾讯云的学生套餐ECS服务器,价格120一年,很划算,但是一直也没有拿来使用,刚好最近在学习python,就打算利用起来做爬虫的服务器。 ECS服务器我安装的是centos7.4的系统 然后安装anaconda包。这个包自带了python环境和很多相关的组件包,使用起来特方便 (这个安 […]
2019-12-15Python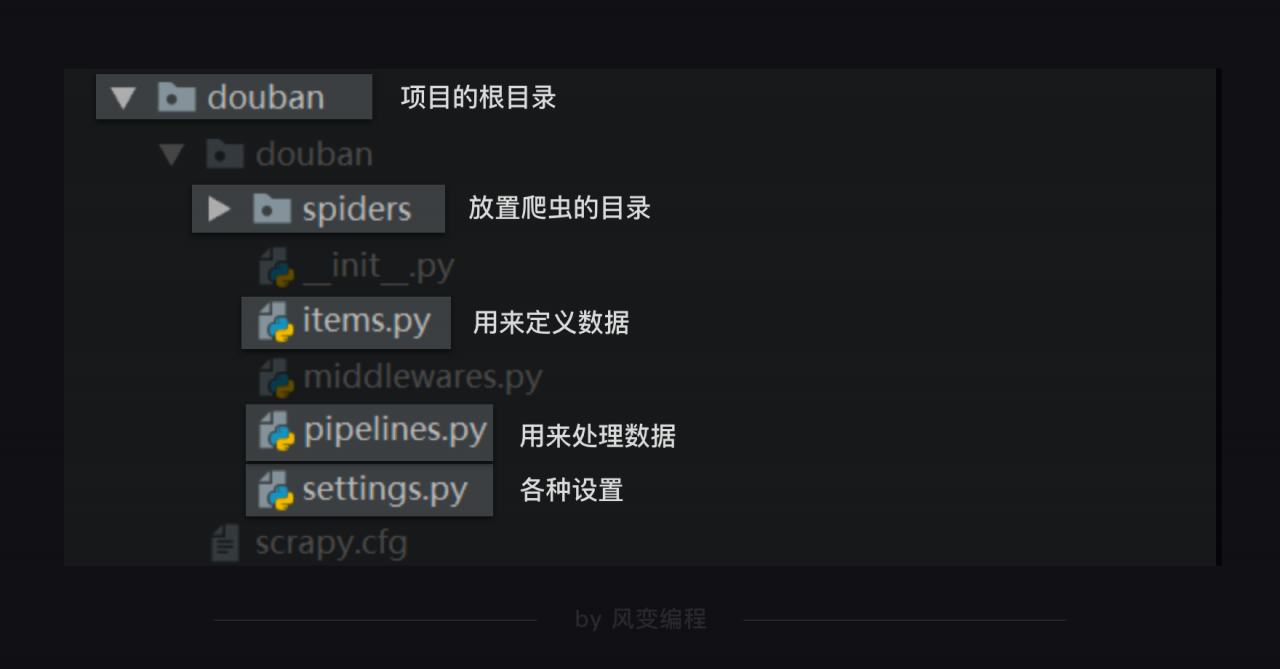
在命令行输入scrapy命令新建项目 scrapy startproject mrle (mrle改成你需要的项目名字) 在spiders目录下新建一个deal.py 的文件来处理整个爬取内容的数据 import scrapy import bs4 import csv from ..i […]
2019-12-14Python写脚本过程中用到了需要随机一段字符串的操作,查了一下资料,对于random.sample的用法,多用于截取列表的指定长度的随机数,但是不会改变列表本身的排序: list = [0,1,2,3,4] rs = random.sample(list, 2) print(rs) print(list) 》 […]
2019-12-13Python
Python使用writerow写入csv文件,字符串被分割成一个字符占一个单元格
问题: w.writerow(“abcdef”) 结果:会一个字符占一个单元格 解决办法:加[] w.writerow([“abcdef”])
2019-12-13Pythonimport requests import json userid = str(‘iamdu’) # 1 可以替换成任何长度小于32的字符串哦 apikey = str(‘A’) # 这里的A,记得替换成你自己的apikey哦~ # 创建post函数 def robot(content): # 图 […]
2019-12-13Python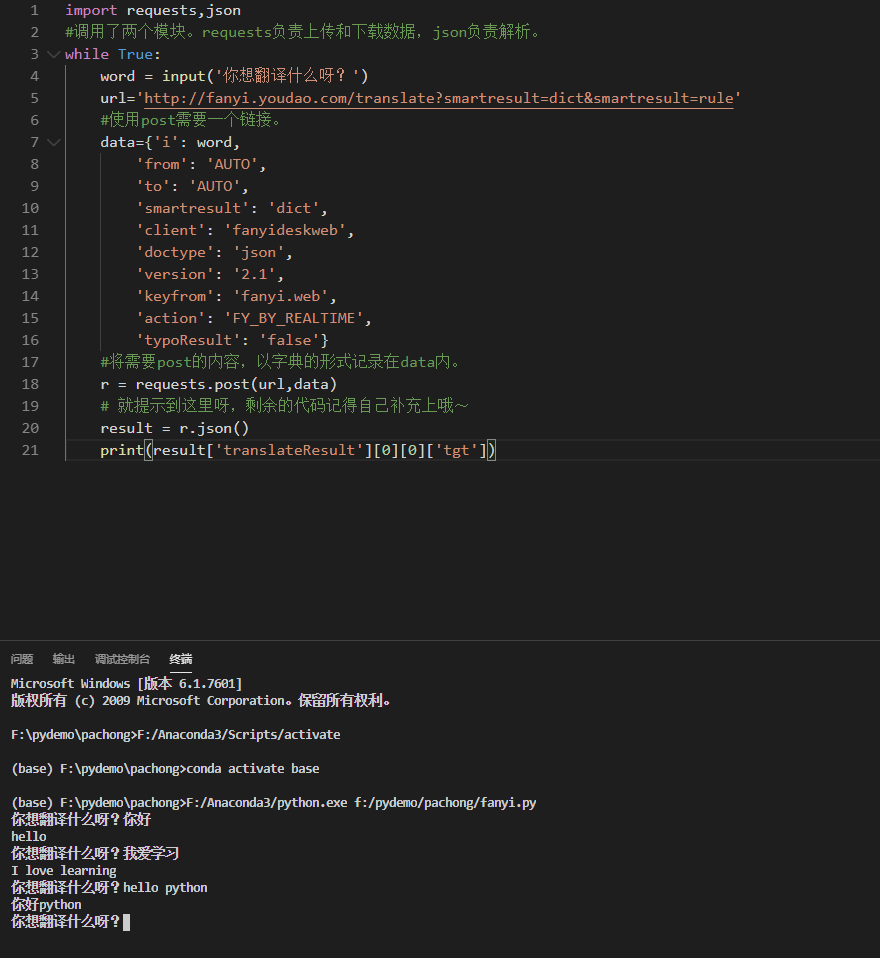
有道翻译有反爬虫机制,它使用了加密技术。如果你的程序报错,你可以通过搜索、查阅资料找到解决方案:尝试把访问的网址中“/translate_o”中的“_o”删除。服务器返回的内容,是json的格式。我们可以用处理列表、处理字典的手段来提取翻译。 import requests,json #调用了两个模 […]
2019-12-12Python
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!