



我的业务
-
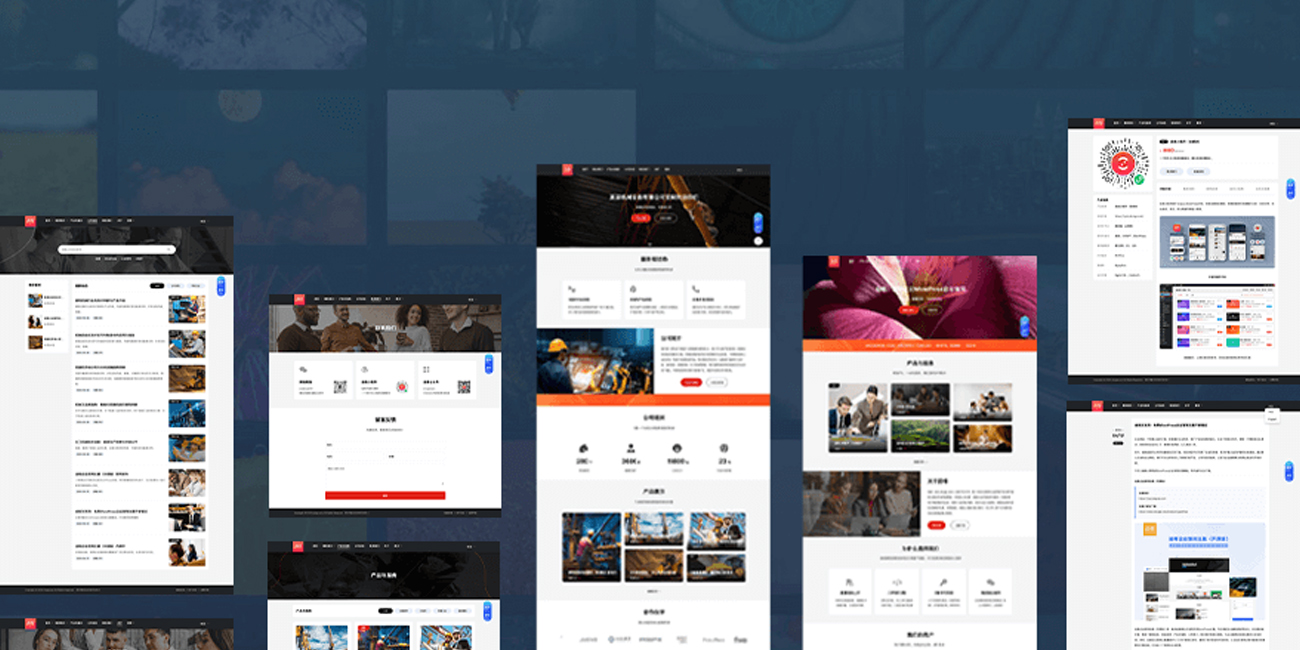 WordPress模板主题开发定制
WordPress模板主题开发定制 -
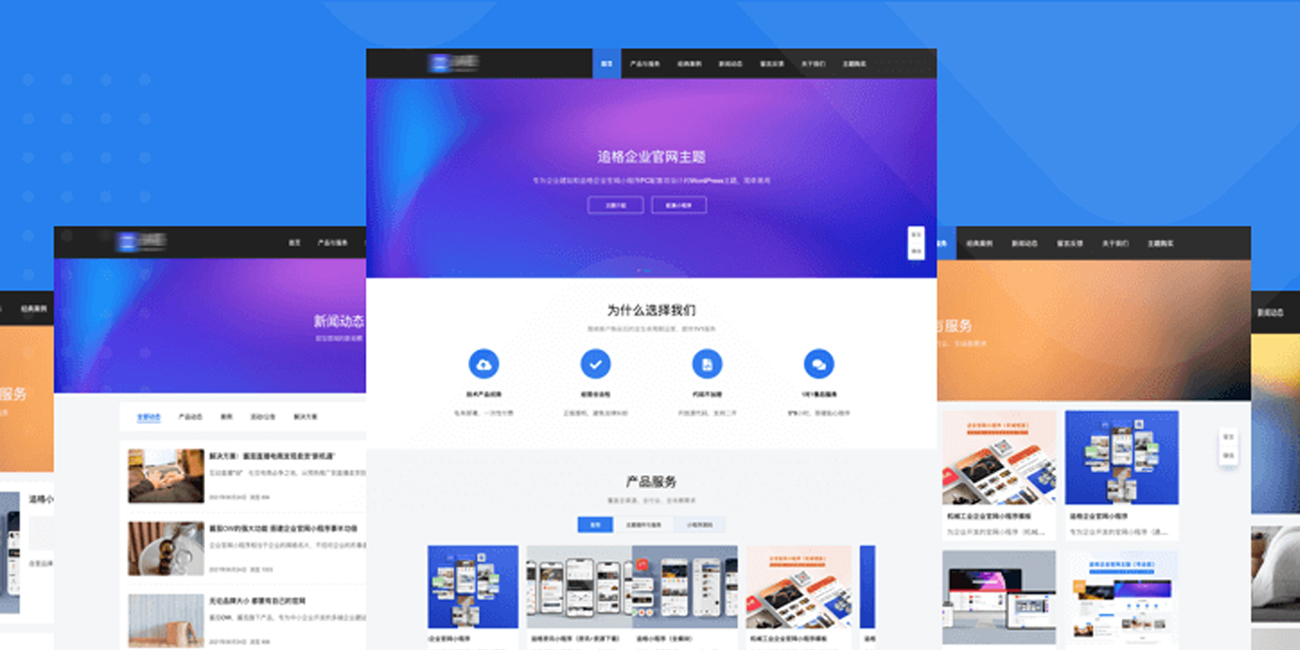 企业官网建设
企业官网建设 -
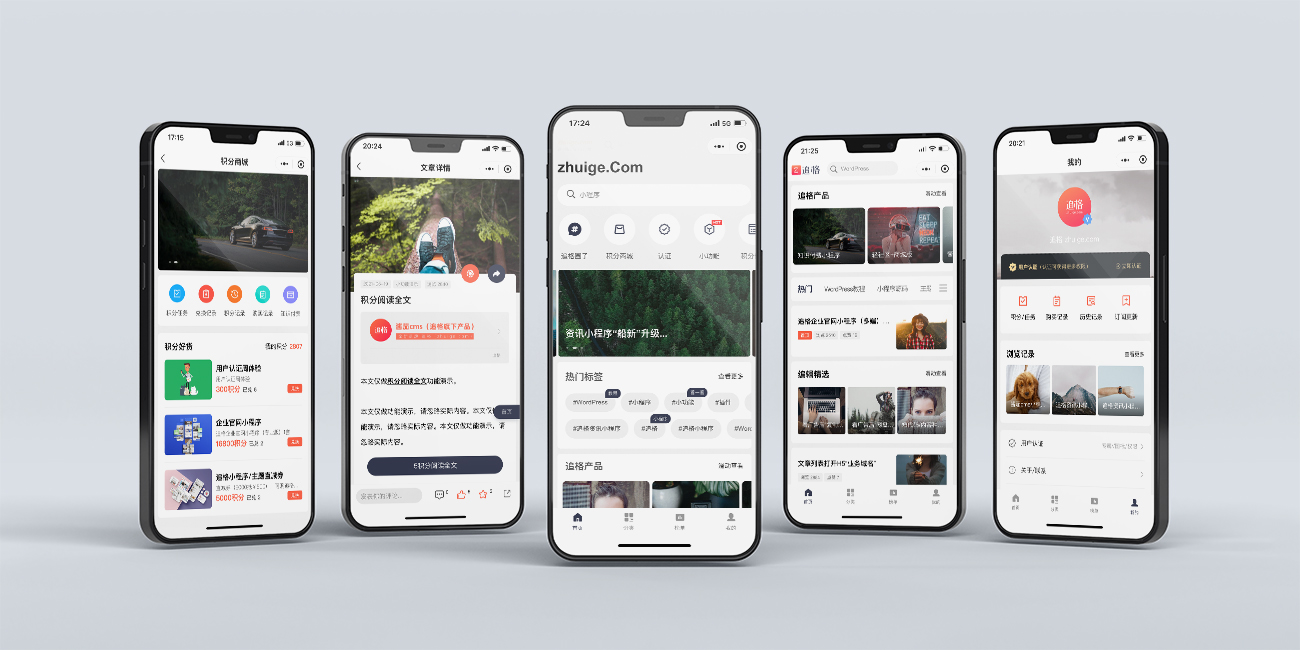 小程序制作开发
小程序制作开发
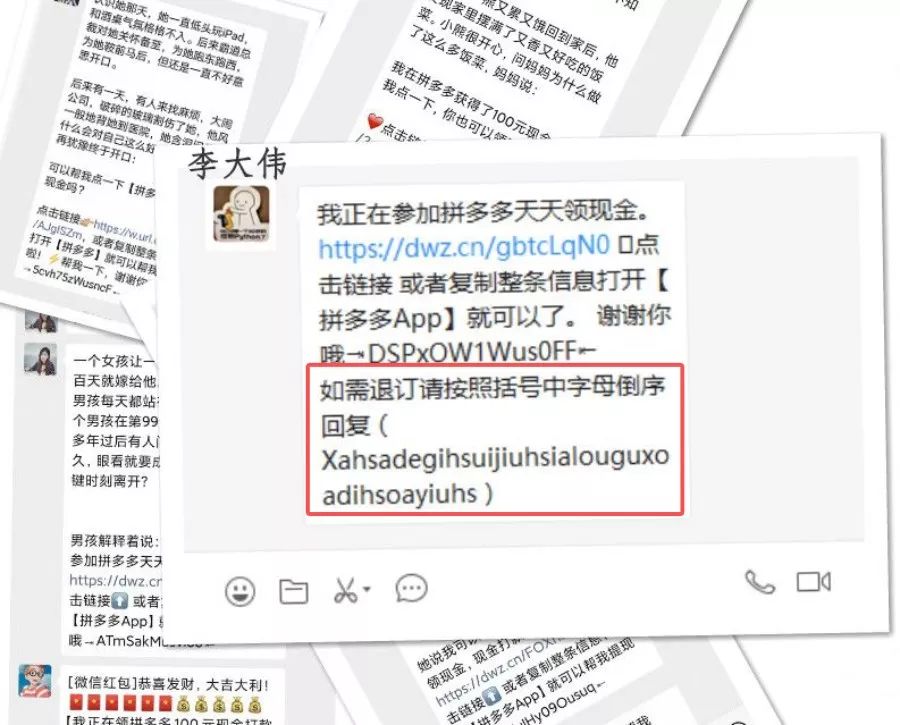
刚屏蔽了天猫的盖楼,没想到大家把拼多多链接玩出了花样 李大伟你可看好了! 我一定要退订! 主要用到python中列表的 insert() 方法 其中参数 obj: 要插入列表中的对象; index:对象 obj 需要插入的索引位置。 方法就是将字符串中的字母都提取出来, […]
2020-01-20Python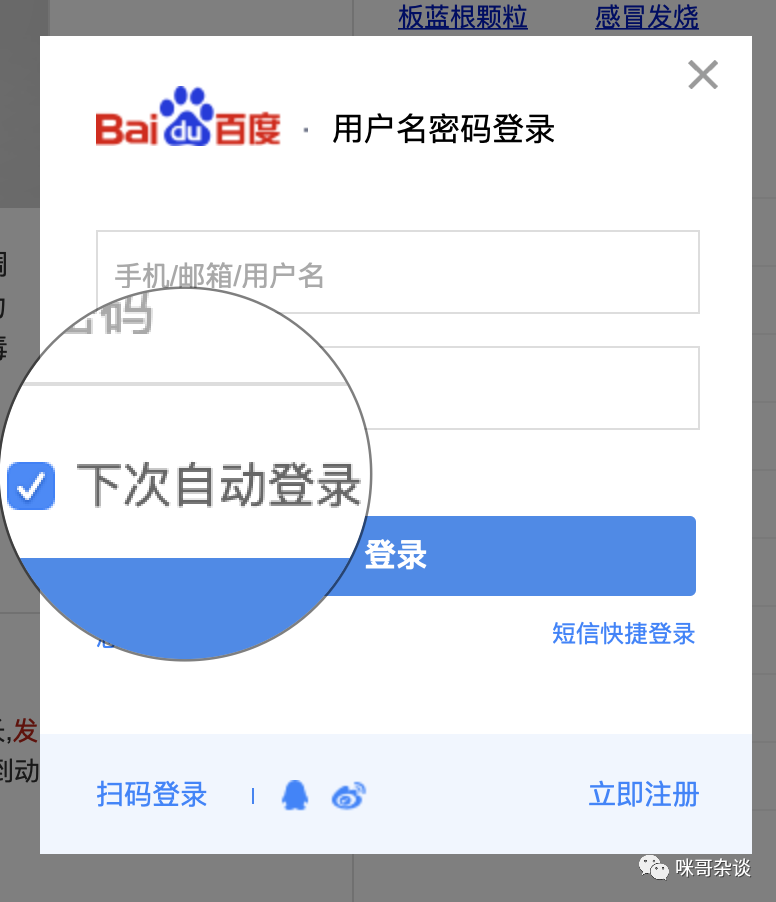
本篇阅读时间约为 5 分钟。 1 前言 你还在为使用浏览器的时候,忘记密码而烦恼吗?今天要分享的不为人知的小技巧,利用前端技术原理来帮助你找回原密码。在我们使用各种网站登录时,总会勾选上记住密码这一项。 但长时间依赖记住密码,难免有遗忘的情况,那么,如何才能知道自己的密码是多少呢? 2 浏览器技巧 […]
2020-01-20Python
你常看到 Python 代码中的 yield 到底是什么鬼?
之前给大家说过,久久会解锁一篇 VIP 中的文章给大伙乐呵乐呵,其实是被吐槽没有试看文。 好吧,今天就是这么出其不意攻其不备,就随便挑选一篇出来给你瞧瞧货色: yield 到底是干屌的? 首先我们来看下这两个列表的区别: 可以看到, list_1 是 [i for i […]
2020-01-15Python
python爬虫反爬 | 对方是如何丧心病狂的通过 css 加密让你爬不到数据的
这次我们来说点爬虫稍微进阶一点的 关于如何破解 css 加密后的数据 别急 我们先站在对方的角度 想一想 假如我们现在有一个网站 这个网站有些关键的数据信息 不想给别人那么轻易的爬取到 你会怎么做呢? 一个可执行的方法 就是将关键数据通过 css 加密 这样的话 当别人通过 requests 来 请 […]
2020-01-15Pythonb = [a for a in range(10)] print(b) 输出的结果[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2020-01-15Python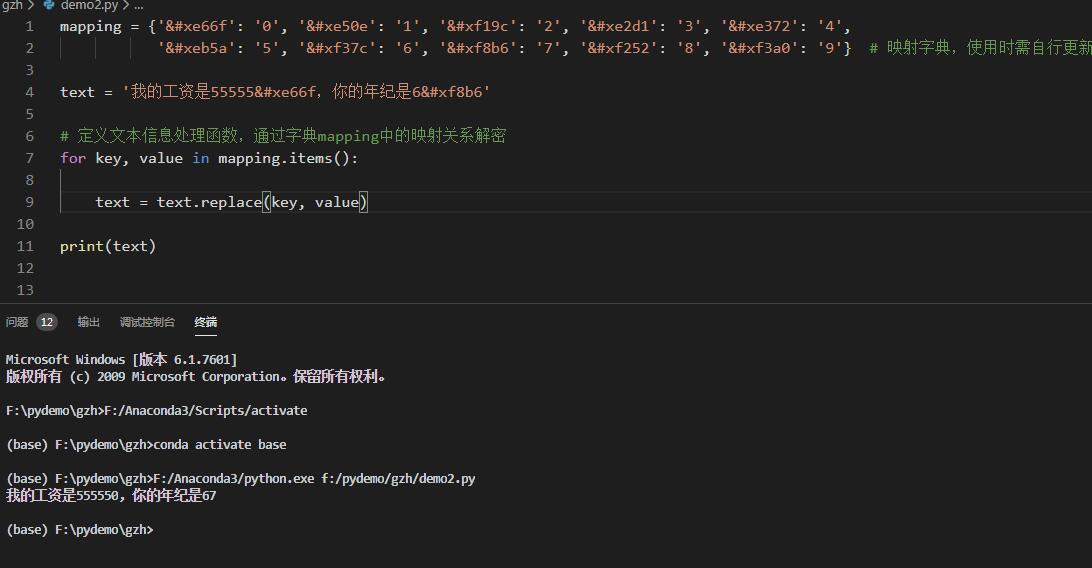
for key, value in xxx.items()用法
mapping = {‘’: ‘0’, ‘’: ‘1’, ‘’: ‘2’, ‘’: ‘3’, ‘’: ‘4’, ‘’: ‘5’, ‘’: ‘6’, […]
2020-01-15Python
1.网页分析 爬虫嘛,最主要还是先分析分析网页。 首先,用谷歌浏览器打开“实习僧网站”,输入“数据挖掘”搜索,然后检查以下内容: 网页的加载方式:发现是纯静态加载的,说明数据就在html文件里; 如何翻页:通过观察发现网站是通过URL的参数“k”控制职位关键字,参数“p”控制页码,所以“数据挖掘”职 […]
2020-01-15Python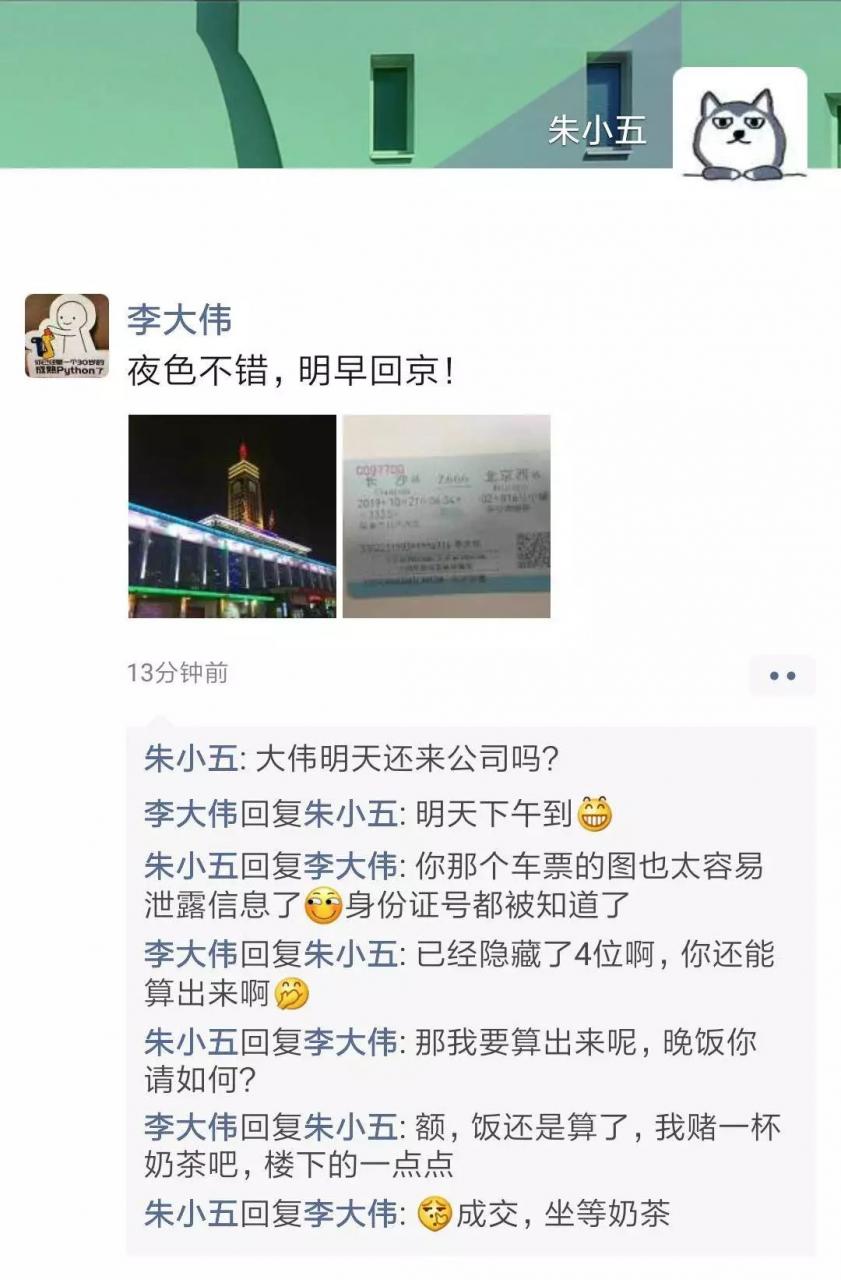
一、一张火车票引发的赌局 事情的经过是这样的: 我的同事李大伟最近出差去了。 昨晚睡觉前翻了翻朋友圈, 就跟他愉快地 互怼 交流了起来。 估计是他想起了我朱小五从不打无把握之赌,后面就怂了。 一杯奶茶嘛,也可以接受, 像杰伦一样快乐就好啦。 二、计算概率 开工。 先看看李大伟的朋 […]
2020-01-14Pythonimport requests # 引用requests模块 url = ‘https://jixianci.fkdmg.com/fkapi/cha_jixianci.php?typ=cha&ajax=1&formhash=75666097’ # 请求歌曲评论的url参数的前面部分 […]
2020-01-13Python
参考教程: https://www.ixigua.com/i6779202162154013188/
2020-01-13Python


DU
DU,80后,误入互联网,终身学习者,博客分享自己的学习记录和生活点滴,随心记录,胡乱折腾。任何业务上的合作欢迎加V:iiamdu
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!