



我的业务
-
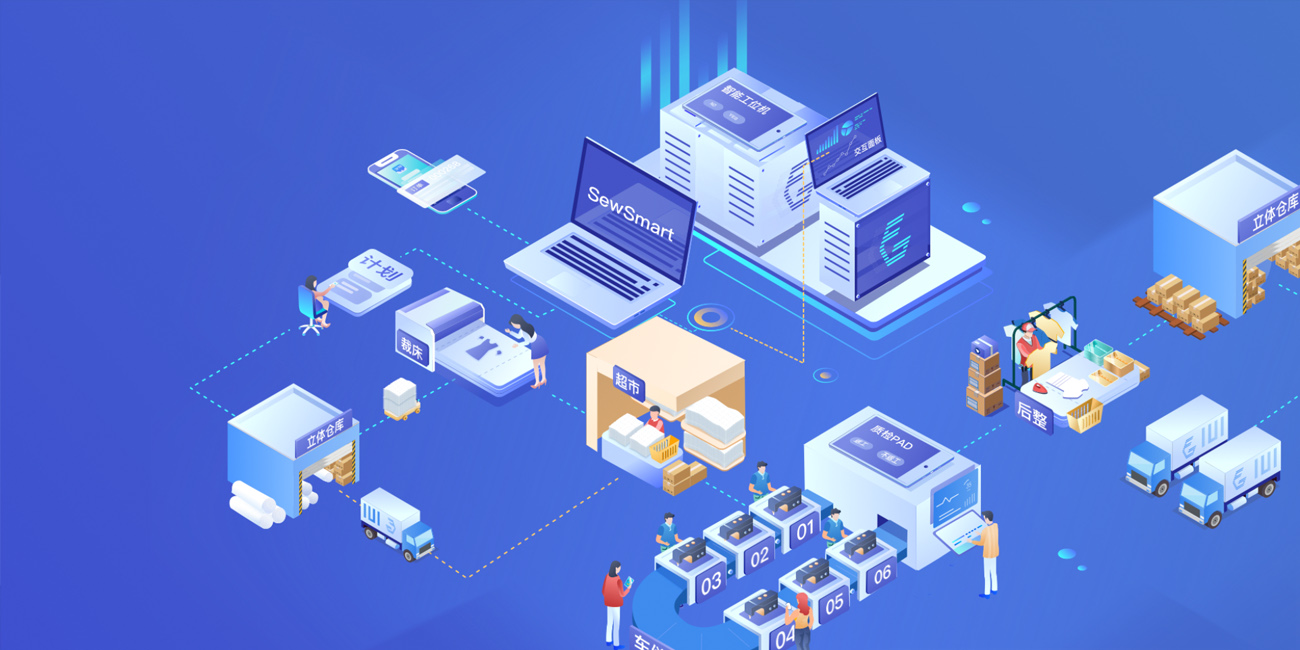 服装生产管理软件
服装生产管理软件 -
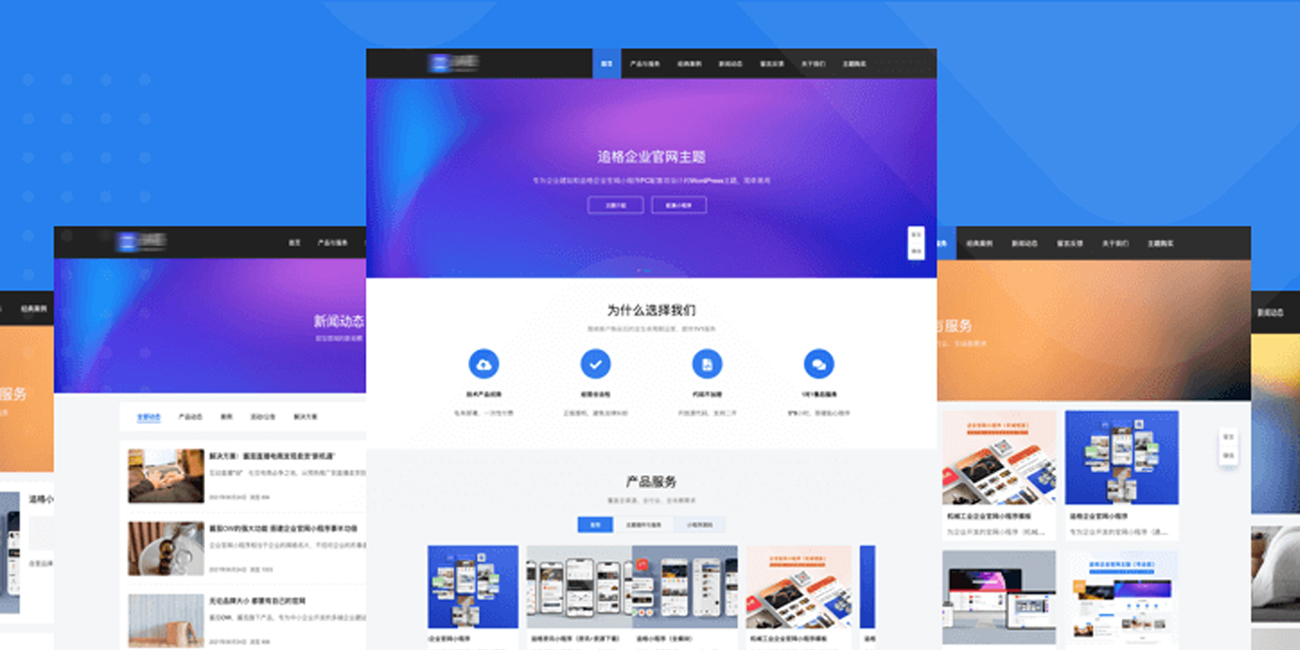 企业官网建设
企业官网建设 -
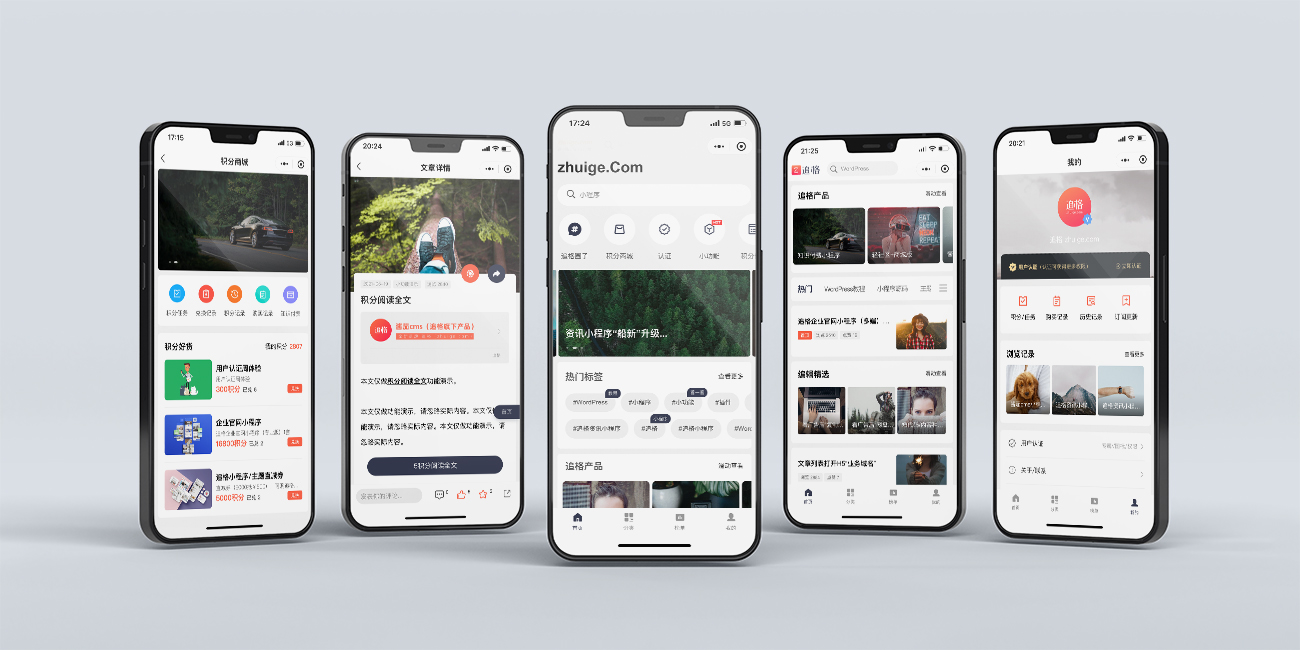 小程序制作开发
小程序制作开发
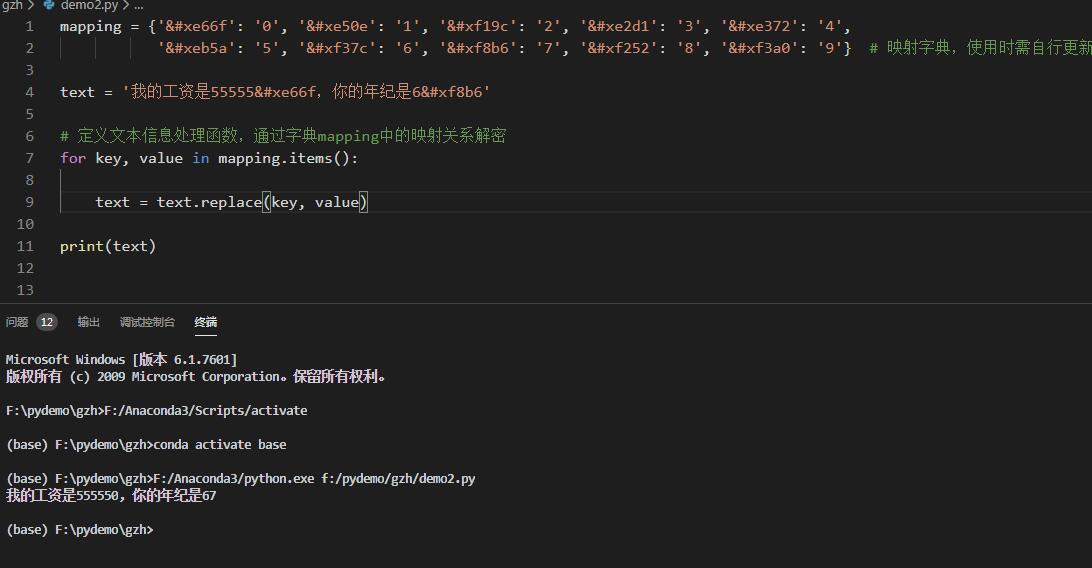
for key, value in xxx.items()用法
mapping = {‘’: ‘0’, ‘’: ‘1’, ‘’: ‘2’, ‘’: ‘3’, ‘’: ‘4’, ‘’: ‘5’, ‘’: ‘6’, […]
2020-01-15Python
1.网页分析 爬虫嘛,最主要还是先分析分析网页。 首先,用谷歌浏览器打开“实习僧网站”,输入“数据挖掘”搜索,然后检查以下内容: 网页的加载方式:发现是纯静态加载的,说明数据就在html文件里; 如何翻页:通过观察发现网站是通过URL的参数“k”控制职位关键字,参数“p”控制页码,所以“数据挖掘”职 […]
2020-01-15Python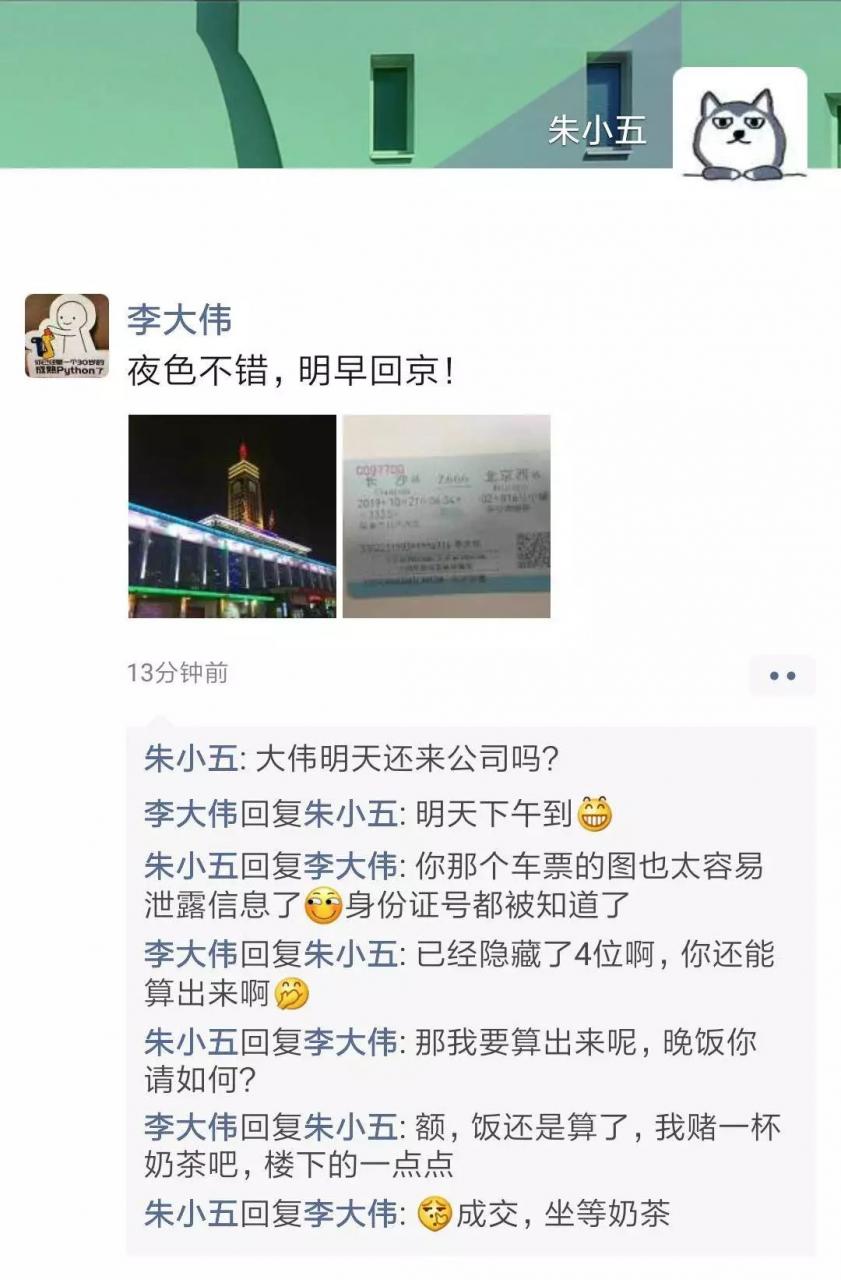
一、一张火车票引发的赌局 事情的经过是这样的: 我的同事李大伟最近出差去了。 昨晚睡觉前翻了翻朋友圈, 就跟他愉快地 互怼 交流了起来。 估计是他想起了我朱小五从不打无把握之赌,后面就怂了。 一杯奶茶嘛,也可以接受, 像杰伦一样快乐就好啦。 二、计算概率 开工。 先看看李大伟的朋 […]
2020-01-14Pythonimport requests # 引用requests模块 url = ‘https://jixianci.fkdmg.com/fkapi/cha_jixianci.php?typ=cha&ajax=1&formhash=75666097’ # 请求歌曲评论的url参数的前面部分 […]
2020-01-13Python
参考教程: https://www.ixigua.com/i6779202162154013188/
2020-01-13Python参考:https://blog.csdn.net/sandalphon4869/article/details/90272247 参数表示: (x:float) 表示x是float类型 (x:float=0) 表示x是float类型,默认值是0 ->float 返回一个float类型的数 一、 […]
2020-01-12Python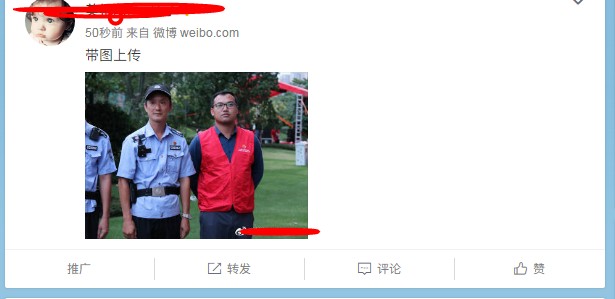
selenium +PhantomJS自动发布带图文微博(涉及图片上传 autoit操作)
from selenium import webdriver from bs4 import BeautifulSoup import time import os from selenium.webdriver.common.desired_capabilities import DesiredC […]
2020-01-10Python
from selenium import webdriver from bs4 import BeautifulSoup import time from selenium.webdriver.common.desired_capabilities import DesiredCapabilitie […]
2020-01-09Pythonfrom selenium import webdriver from bs4 import BeautifulSoup import time # browser = webdriver.PhantomJS() browser = webdriver.Chrome() browser.get(‘h […]
2020-01-09Python
wordcloud是功能强大的词云展示第三方库。它不仅可根据文本中词语出现的频率等参数绘制词云,还可设定词云的字体,颜色,形状等。需要注意的是,wordcloud库在运行时,需要用到一些依赖库:包括matplotlib库以及图像处理库pillow库。因此,使用该库之前,务必先装好依赖库。和其他第三方 […]
2020-01-08Python


DU
DU,80后,误入互联网,终身学习者,博客分享自己的学习记录和生活点滴,随心记录,胡乱折腾。任何业务上的合作欢迎加V:iiamdu
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!